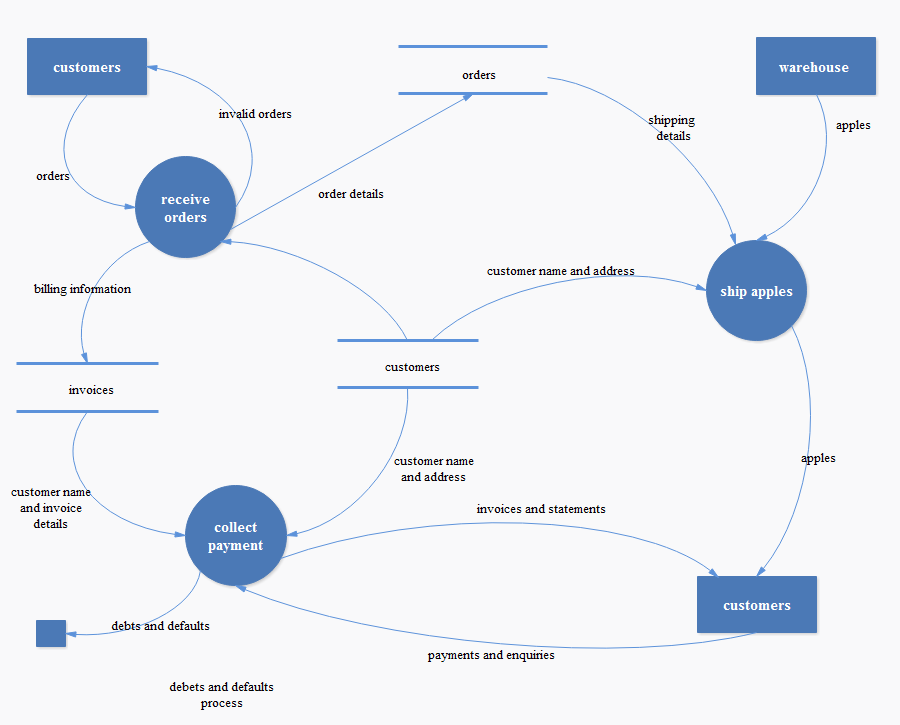
关于数据流程图 - DFD
数据流图(Data Flow Diagram,DFD)也称数据流程图或数据流向图,它是一种便于用户理解、分析系统数据流程的图形工具。它摆脱了系统的物理内容,精确地在逻辑上描述系统的功能、输入、输出和数据存储等,是系统逻辑模型的重要组成部分。[1]
数据流图分析法是结构化分析与设计方法(SSADM,Structured Systems Analysis & Design Method)的重要方法之一。分析产生的数据流图,和数据字典等一同构成结构化分析方法的核心输出。
历史
数据流图在 1970 年代后期由计算先驱 Ed Yourdon 和 Larry Constantine的《结构化设计》一书普及开来。他们基于 David Martin 和 Gerald Estrin 的“数据流图”计算模型。结构化设计理念在软件工程领域起飞,DFD方法随之起飞。DFD 表示法借鉴了图论,最初用于运筹学,以对组织中的工作流进行建模。除了Edward Yourdon和Larry Constantine,还有三维促成 DFD 方法论兴起的专家,分别是 Tom DeMarco、Chris Gane 和 ...

产品设计参考百则
产品设计参考百则
伯斯塔法则
【定义】
系统/产品应保有一定程度的容错能力,在设计中表现为允许用户进行任何操作,即便是错的或无效的。
【案例】
Bilibili安卓端头部区域除了【搜索栏】和其他几个按钮之外,任意地方点击都能进入侧边栏,及时没有点击到【三条杠】,因为这三条杠是在是太小了,用户极有可能没有点击到,所以干脆扩大了可触法的热区。
美好即用效应
【定义】
当界面被设计得足够美观时,用户往往会容忍一些较为轻微、影响较小得可用性问题
【案例】
微信读书使用横向滑动得卡片,一屏一张卡片一个主题,相比较其他读书类APP(比如起点、京东读书)而言,这种界面得组织方式浏览效率不高,且浪费大量屏幕空间,单简洁、优雅得设计,就有了让我们多花一点耐心和操作成本看下去的欲望。
刺激作用
【定义】
刺激记忆中的特殊概念,借此影响后续行为。如何导入的刺激所激活的概念,跟先前已存在的需求或目标一致,刺激作用就能发挥有效的影响力。
【案例】
在电影开幕前秀出某人喝汽水的影像,会对口渴的人产生效应,诱使更多人去买汽水,但对不觉得口渴对人,就没有效果。
雅各布定律
【定义】
用户将大部分时间花在别人家对网站( ...
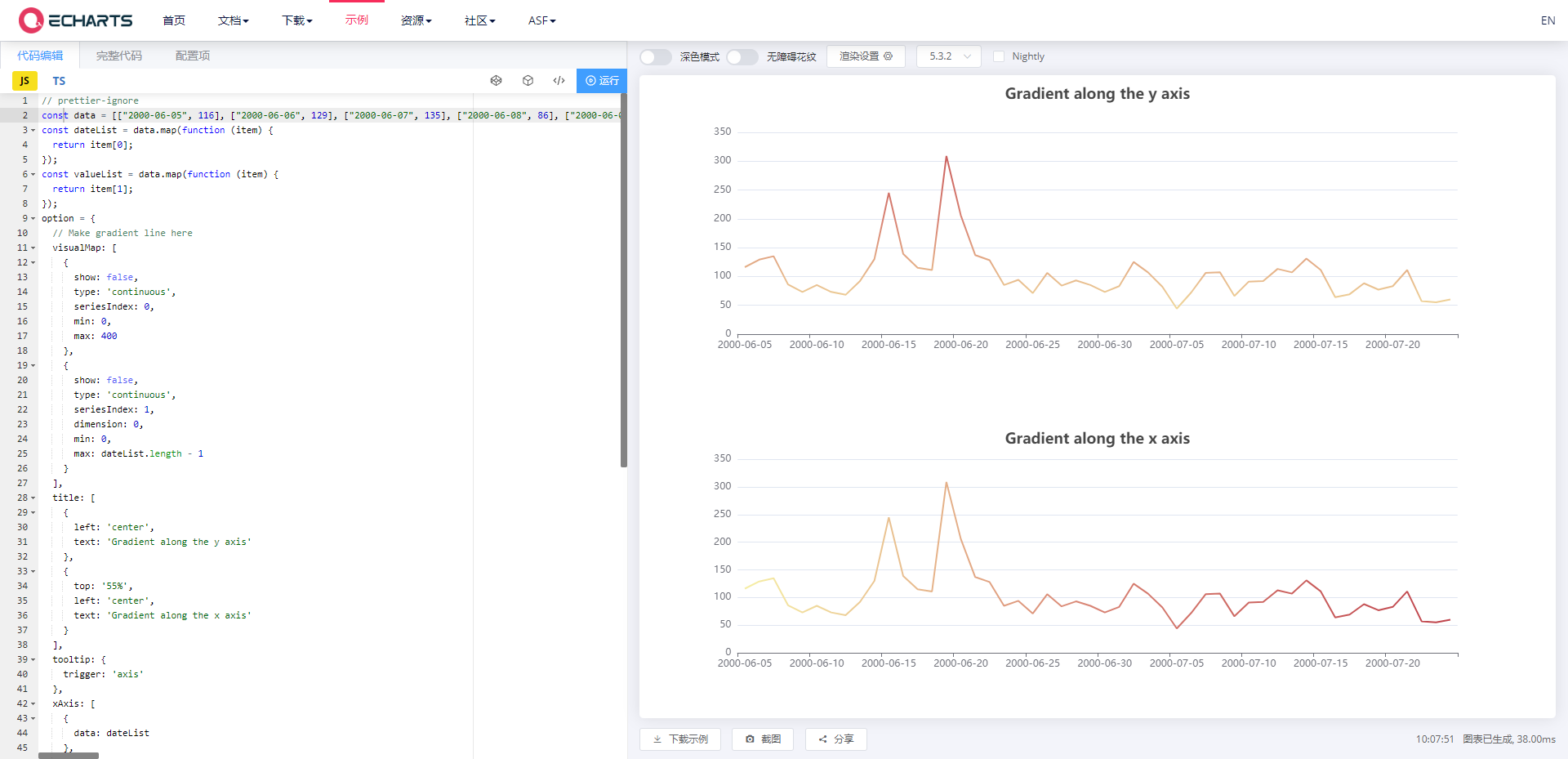
如何在 Axure 中插入 Echarts 代码
基本操作
如果想要在Axure原型中执行简单的JavaScript代码,只需要将交互事件设置为打开链接,链接到URL或外部网址,在函数输入框中输入javascript:,后面补充需要执行的js代码即可,例如
javascript:alert('利用Axure JS的伪协议方式,执行JS代码')
既然Axure支持通过JS为协议执行JS代码,因此也可以直接引入Echarts JS库,直接在Axure中执行图表的渲染和绘制。
具体操作步骤如下:
创建用于展现图表的矩形,并为其命名(命名在JS中需要引用,可以说是变量名。尽量符合图表含义。)
设置载入时交互事件,打开链接,链接到URL或外部网址。
在Option配置项中输入如下代码。p.s. 代码里面不能有任何如“/*”、“*/”、“//”的注释符号,Echarts中直接复制过来的代码一般都存在注释,需要手动删除,否则无法在Axure中显示。
javascript:$axure.utils.loadJS('https://fastly.jsdelivr.net/npm/echarts@5.3.2/dist/e ...

《组织的力量:增长的隐性曲线》读书笔记
阅读笔记
Part 1
企业的增长是连续性的吗?
不是,企业的增长,非连续是正常,连续是不正常。
为什么只有少数企业能跨越非连续性增长?
像华为阿里这类公司,并不是通过野蛮生长,紧追风口获得发展,而是通过研究客户需求,企业可以提供哪些有价值的产品来实现可持续经营。
跨越非连续性增长的两块踏板?
显性踏板是指业务,隐性踏板组织。
亚马逊的第一曲线也就是显性曲线是怎么长出来的?
来自于创业时候的企业愿景和使命,因为愿景和使命决定着核心战略,当核心战略要落地的时候,通过组织保障,启用隐性曲线,让公司从文化到团队到团队能力,都能够跨越到第二曲线去。
为什么一直跌到3000亿美金?
微软99年最高峰达到6000亿美金,随后一直跌到3000亿美金。因为他没有找到移动战略
(吐槽此观点:莫名其妙!极不负责任!一如微软如此庞大的企业仅因没有移动战略所以蒸发3000e? 巨头的倒下,往往都不是一个两个具体人或事的缘故,背后的经济、政治、乃至机缘巧合都在起综合作用。能成为企业的领导、CEO,都不是大傻子,而且必然有过人的本事,他甚至对创新的想法比任何人还早还好,但是大企业要顾及方方面面 ...

Markdown 数学公式
Markdown 数学公式
行内与独自一行
行内公式:将公式插入到本行内,符号:$公式内容$,如:xyzxyzxyz
独行公式:将公式插入到新的一行内,并且居中,符号:$$公式内容$$,如:$$xyz$$
上标、下标与组合
上标符号,符号:^,如:x4x^4x4
下标符号,符号:_,如:x1x_1x1
组合符号,符号:{},如:168O2+2{16}_{8}O{2+}_{2}168O2+2
汉字、字体与格式
汉字形式,符号:\mbox{},如:V_{\mbox{初始}}
字体控制,符号:\displaystyle,如:x+yy+z\displaystyle \frac{x+y}{y+z}y+zx+y
下划线符号,符号:\underline,如:x+y‾\underline{x+y}x+y
标签,符号\tag{数字},如:\tag{11}
上大括号,符号:\overbrace{算式},如:a+b+c+d⏞2.0\overbrace{a+b+c+d}^{2.0}a+b+c+d2.0
下大 ...

Axure common shortcuts
Axure common shortcuts
基本快捷键
打开:Ctrl + O
新建:Ctrl + N
保存:Ctrl + S
退出:Alt + F4
打印:Ctrl + P
查找:Ctrl + F
替换:Ctrl + H
复制:Ctrl + C
剪切:Ctrl + X
粘贴:Ctrl + V
快速复制:Ctrl+D&点击拖拽+Ctrl
撤销:Ctrl + Z
重做:Ctrl + Y
全选:Ctrl + A
帮助说明:F1
输出快捷键
生成原型预览:F5
生成规格说明:F6
更多的生成器和配置选项:F8
在原型中重新生成当前页面(不弹出新窗口生成预览):Ctrl +F5
工作区域快捷键
下页:Ctrl + Tab
上页:Ctrl + Shift + Tab
关闭当前页:Ctrl + W
垂直滚动: 鼠标滚轮
横向滚动:Shift + 鼠标滚轮
放大缩小:Ctrl + 鼠标滚轮
页面移动:Space + 鼠标右键
隐藏网格:Ctrl + ’
对齐网格:Ctrl + Shift + ’
隐藏全局辅助线:Ctrl + .
隐藏页面辅助线:Ctrl + ,
对齐辅助线:Ct ...
爬虫 - 豆瓣 Top 250
豆瓣作为一款集书影音评论的网站 ,却还提供了各种其他有趣的多服务,这更像是一个社区。往往这样的网站中会有非常多有趣的数据,今天就来尝试爬一下,做一个数据集出来。起初就在这个网站看到有一个专门的Top250榜单,官方说是根据书/电影/音乐所看过或听过的人数,以及该项目所得的评价等综合数据,通过算法分析 产生的。那今天的主要目的就来爬一下这些个Top250。代码写的很水,希望能有人不吝赐教。
爬取目标
豆瓣电影 Top 250 >> 电影名,导演,年份,制片地区,电影分类,豆瓣评分,评论人数,描述 <<
豆瓣图书 Top 250 >> 书名,作者,售价,豆瓣评分,评论人数,描述 <<
豆瓣音乐 Top 250 >> 名称,作者,年份,类型,介质,风格,豆瓣评分,评论人数 <<
具体实现
爬取豆瓣电影 Top 250
#!/usr/bin/env python# -*- encoding:utf-8 -*-"""@author: Yu@contact: kinomu@sina.c ...
Neo4j Cypher 语法参考
本文以 Neo4j 官网上的 Neo4j Cypher Refcard 3.4为基准,通篇翻译以作学习。即便版本发生改变 ,但其语法以及其作用不会发生太大的变化,放心食用,个人建议原文口味更佳。
Read Query Structure
Read Query Structure
[MATCH WHERE]
[OPTIONAL MATCH WHERE]
[WITH [ORDER BY] [SKIP] [LIMIT]]
RETURN [ORDER BY] [SKIP] [LIMIT]
MATCH
MATCH
MATCH (n:Person)-[:KNOWS]->(m:Person) WHERE n.name = ‘Alice’ [^1]
MATCH (n)–>(m) [^2]
MATCH (n {name:‘Alice’})–>(m) [^3]
MATCH p = (n)–>(m) [^4]
OPTIONAL MATCH (n)-[r]->(m) [^5]
[^1]: 节点模式(Node ...
Neo4j - Cypher Query Language - 入门指引
Cypher Query Language (CQL) 是 Neo4j 所使用的开放图形查询语言。Cypher 的语法提供了一种方式(类SQL)来匹配图中的节点和关系,也就是模式。如果具备 SQL 的基础,那么学习起 Cypher 就能变得更加容易。这是这篇指引推崇的做法 —— 先掌握SQL基础,再学习 Cypher。除此之外,还需要具备图形数据库和属性图模型的基本概念,以便更好的理解 Cypher 查询。
节点 Nodes
Cypher 使用 ASCII-Art 来表示模式。就像一个⚪一样,用双括弧来围绕节点,例如(节点A)。在之后如果我们想要引用这个节点,只需要使用一个变量例如(node_a) ,如果关注的问题与节点无关,还可以使用空括弧()。一般情况下,节点还会使用标签来区分实体,同时在Neo4j中,使用标签是一种执行优化的方案。以节点A为例,为其添加标签,如(节点A:标签1)。
match (节点A:标签1) return 节点A.某属性
在进行节点查询时,有时还会用到(emp:Employee)-->(dep:Department)这样的模式,用以查看例如emp.na ...

K-近邻算法实践:Glass Classification - Kaggle Datasets
可从GitHub(Glass Classification)下载本文源码以及样本数据集
前言
本文主要目的是通过 KNN 也就是 k-近邻算法 来实现一个Glass Classiciation,文中使用的数据来自 Kaggle Datasets ,可以从该页面下载这份数据文件,也可以直接从我 Github 上下载源代码,源代码包括了本文所有内容。 k-近邻算法是 Machine Learning 的一个入门级算法,具备有效性以及易学习。在文章中,我希望通过强调 k-近邻算法 的基本理论,以及如何使用距离测量的方法来进行分类,理论部分的内容十分重要,这关乎到你是否能够理解在面对什么样的数据时可以采用 KNN ,而什么时候又不是那么的适合。
简单来说,k-近邻算法采用测量不同特征值之间的距离,来对数据进行分类。这个距离的计算也是十分简单的,如果你不知道什么是 欧式距离公式 (也有人称它为欧几里得度量法),那么建议先去了解一下,它是比较简单易懂的。另外代码实现部分,将会使用Python,所以前提要求是你需要学会最基本的Python语法。如果你不懂Python——互联网上有非常多关于 P ...