知识图谱 Knowledge Graph
Part I:知识图谱概念
知识图谱这个概念最早是由 Google 于 2012年5月 率先提出的,目的是将用户搜索的结果进行知识系统化,让每一个关键字都拥有一个完整的知识体系,从而真正意义上实现基于内容检索,提高搜索质量。Google 提出的知识图谱在某种程度上,可能将被指向下一代智能搜索引擎的核心。借用幸格博士的一句话:The world is not made of strings , but is made of things . 即构成这个世界的并非是字符串,而是实体。
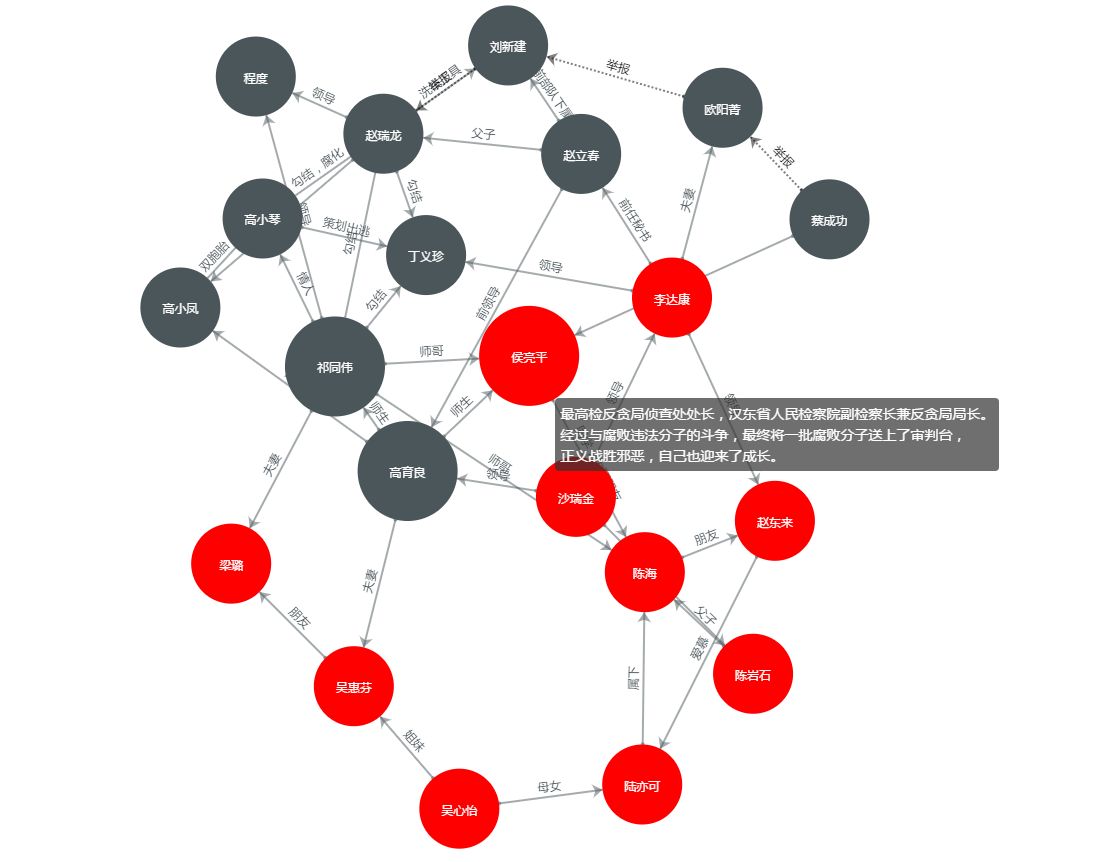
上面这张图谱表明了《人民的名义》中各个角色之间的关系。可以看出如果两个人之间存在关系,则会被一条线连接在一起,这样被连接起来的两个对象,可以称之为 **实体(Entity)**或 节点(Point), 而这条线可以被称之为 关系(Relationship) 或 边(Edge)。
这张图谱的实体数量并不是非常多,所存在实体间关系也能很清楚的看清,但是如果涉及到实体成百上千的时候呢?再来看看知名电影《Start Wars》中228种实体构成的知识图谱。
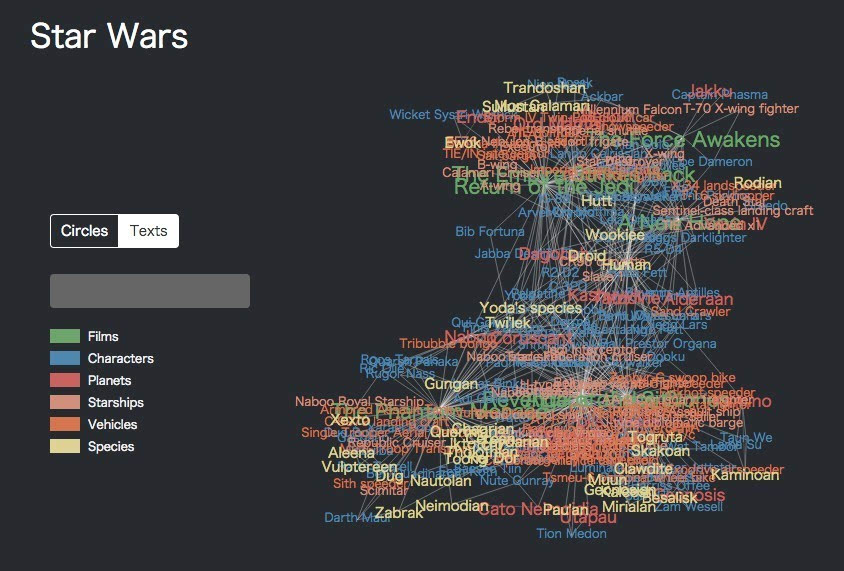
错综复杂的关系这个时候已经不是人脑可以在短时间内理解清楚的了。但根据这两张图,应该不难理解,知识图谱本质上就是如这两张图一样,展示出来的是一个语义网络,这是一种基于图的数据结构,是由 实体(节点)和 关系(边)组成的。
这里对提及的语义网络做一个简单的说明:语义网络是由数据构成的,向用户提供的是一个查询环境,其核心要以是以图形的方式向用户返回经过加工和推理的知识。而知识图谱技术则是实现智能化语义检索的基础。
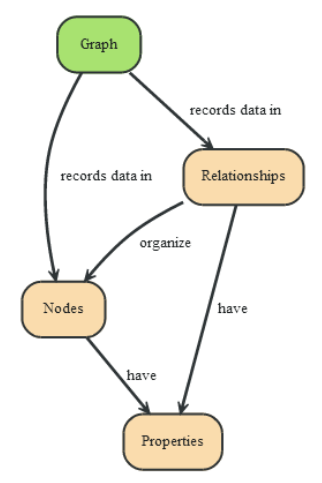
总而言之,知识图里的每一个节点表示显示世界中存在的实体,每一条边为实体与实体之间的关系。这样就形成了知识图谱的基本组成单位,即 实体 —— 关系 —— 实体 这样的三元组,同时还有实体的相关属性和值对。
Part II:知识图谱架构
知识图谱的架构包括了知识图谱自身的逻辑架构以及构建知识图谱所采用的技术架构。
Part II - A:逻辑架构
在逻辑的层面可以将知识图谱划分为两个层次: 数据层以及模式层。
-
数据层:用以存储真实的数据。
-
模式层:是数据层之上的一个层,是知识图谱的核心部分,存储的是已经通过提炼后的知识。通常是使用本体库来管理这一层。 本体库类似OO思想中类的概念,存储者知识图谱的类。
这两个层之间的区别可以通过下面这个例子来进行理解:
模式层:实体—关系—实体,实体—属性—值
数据层:罗贯中—作品—《三国演绎》,罗贯中—朝代—明朝
Part II - B:技术架构
知识图谱的整体架构可以用下图表示,其中虚线框中的部分为知识图谱的构建过程,同时也是它的更新过程 。
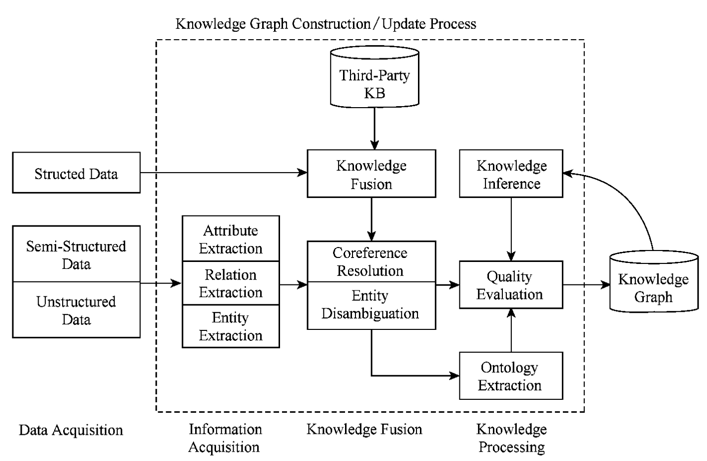
按照技术架构,我们可以理清知识图谱的构建思路。首先是海量数据,可能是结构化数据,或非结构化数据,或半结构化数据,然后我们基于数据来构建知识图谱。这一个步骤主要是通过一系列自动化或半自动化的技术手段,来从原始数据中提取出知识要素,即实体关系,并将其存入知识库的模式层和数据层。
构建知识图谱是一个迭代更新的过程 ,根据知识获取的逻辑,每一轮迭代都包含主要三个阶段:
- 信息抽取(Information Acquisition): 从数据源中提取出实体、属性以及实体间的相互关系,在此基础上形成本体化的知识表达;
- 知识融合(Knowledge Fusion): 在获取到了新的知识之后 ,需要进行对新知识的整合,以消除矛盾和歧义。 比如某些实体可能有多种表达,某个特定的成为也许对应多个不同的实体等;
- 知识加工(Knowledge Processing):对于经过融合的新知识,需要经过质量评估之后(部分需要人工参与甄别),才能够将合格的部分加入到知识库中 ,以确保知识库的质量保持在较高的水准上。
Part II - C:知识图谱的展示
上述已经提到说数据的来源无非为三种: 结构化数据、半结构化数据、非结构化数据,前两者多以Wikipedia 以及百度百科为代表的大规模知识库,这些知识库中已经包含了大量半结构化、结构化知识,可以高效的转化到知识图谱中。然而非结构化数据多是文本数据。
知识图谱中的数据存储多以RDF三元组,可以借助 Neo4j 进行可视化展示。
Part III :知识图谱构建
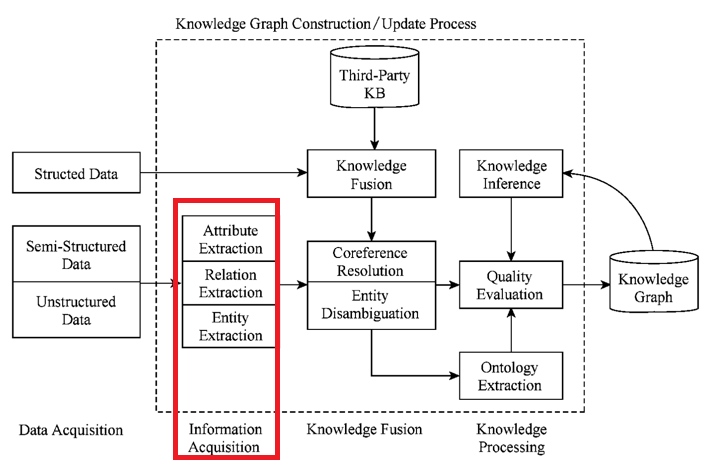
Part III - A :信息抽取(Information Acquisition)
还是按照知识图谱的技术架构图,信息抽取(Information Acquisition) 是知识图谱构架的第一步,其中最为关键的一个问题是: 如何从异构数据源中自动抽取信息得到候选指示单元。我们需要从半结构化以及非结构化数据中进行实体抽取(Entity Extraction)、关系抽取(Relation Extraction)以及属性抽取(Attribute Extraction)。
Part III - A - 1:实体抽取(Entity Extraction)
实体抽取也被成为命名实体识别(Named entity recognition , NER),是指从文本数据集中自动识别出命名的实体。
【 NER 的研究历史 】
- 面向单一领域(single domain):关注如何识别文本中人名、地名等专有名词以及具有具体意义的时间等实体信息:
- 启发式算法 + 人工规则, 实现自动抽取实体的原型系统
- 统计机器学习方法辅助解决命名实体抽取问题
- 监督学习+先验知识
- 关注开放域(open domain):不在限定于特定的知识领域 ,而是面向开放的互联网,研究和解决全网信息抽取问题:
- 人工建立科学完整的命名实体分类体系
- 基于归纳总结的实体类,基于条件随机场(CRF)模型进行实体边界识别,最后采用自适应感知机实现对实体的自动分类
- 采用统计机器学习方法,从目标数据集中抽取出与之具有相似上下文特征的实体,从而实现实体的分类和聚类
- 迭代扩展实体语料库
- 通过搜索引擎的服务器日志,聚类获取新出现的命名实体 —— 已经应用于自动补全技术
实体抽取的质量(准确率和召回率)对后续的知识获取效率和质量影响极大,因此是信息抽取中最为基础和关键的部分。
Part III - A - 2:关系抽取(Relations Extraction)
文本语料经过了实体抽取,得到的是一系列的离散数据,也就是离散实体。为了得到语义信息,还需要从相关的预料中提取出实体之间的关联关系,通过关联关系将实体通过关系联系起来,才能够形成网状的知识结构,研究关系抽取技术的目的,是解决如何从文本语料中抽取实体间的关系这一基本问题
【 关系抽取研究历史 】
- 人工构造语法和语义规则(模式匹配)
- 统计机器学习方法
- 基于特征向量或核函数的有监督学习方法
- 研究重点转向半监督和无监督
- 开始研究面向开放域的信息抽取方法
- 将面向开放域的信息抽取方法和面向封闭领域的传统方法结合
Banko等人提出了面向开放域的信息抽取方法框架(open information extraction,OIE),并发布了基于自监督(self-supervised)学习方式的开放信息抽取原型系统(TextRunner),该系统采用少量人工标记数据作为训练集,据此得到一个实体关系分类模型,再依据该模型对开放数据进行分类,依据分类结果训练朴素贝叶斯模型来识别实体-关系-实体三元组,经过大规模真实数据测试,取得了显著优于同时期其他方法的结果。
TextRunner系统中错误的部分主要是一些无意义或者不和逻辑的实体关系三元组,据此引入语法限制条件和字典约束,采用先识别关系指示词,然后再对实体进行识别的策略,有效提高了关系识别准确率。
Part III - A -3:属性抽取(Attribute Extraction)
属性抽取的目标是从不同信息源中采集特定实体的属性信息。例如针对某个公众人物,可以从网络公开信息中得到其昵称、生日、国籍、教育背景等信息。属性抽取技术能够从多种数据来源中汇集这些信息,实现对实体属性的完整勾画。
【 属性抽取研究历史】
- 将实体的属性视作实体与属性值之间的一种名词性关系,将属性抽取任务转化为关系抽取任务
- 基于规则和启发式算法,抽取结构化数据
- 基于百科类网站的半结构化数据,通过自动抽取生成训练语料,用于训练实体属性标注模型,然后将其应用于对非结构化数据的实体属性抽取
- 采用数据挖掘的方法直接从文本中挖掘实体属性和属性值之间的关系模式,据此实现对属性名和属性值在文本中的定位
Part III - B:知识融合(Knowledge Fusion)
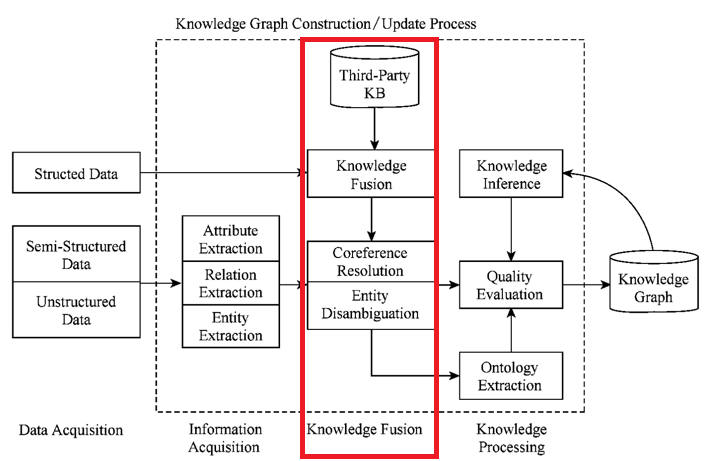
通过信息抽取后,我们从原始的非结构化和板结构化数据中获取到了实体、关系以及实体的属性信息。接下来就是Kownledge Fusion 也就是知识融合
如果把知识融合的过程比喻成拼图,那么信息就是一张张拼图碎片,其本质上就是杂乱无章的,甚至还有错误的碎片,会干扰完成拼图。
若总结起来:
- 信息之间的关系是扁平化的,缺乏层次以及逻辑性
- 知识中还存在大量冗杂和错误的信息
如何解决上述的两个问题就是知识融合中需要做的。这包含着两个部分—— 实体链接 以及 知识合并。
Part III - B - 1:实体链接
实体链接(entity linking)是指对于从文本中抽取得到的实体对象 ,将其链接到知识库中对应的正确实体对象的操作。其基本思想是更具给定的实体指称项,从知识库中选出一组候选实体对象 ,然后通过相似度计算将指称项链接到正确的实体对象。
实体链接的一般流程:
- 从文本中通过实体抽取得到实体指称项
- 进行实体消歧和共指消解,判断知识库中的同名实体与之是否代表不同的含义,以及知识库中是否存在其他命名实体与之表示相同的含义
- 在确认知识库中对应正确实体对象之后,将该实体指称链接到知识库中对应实体
实体消歧:专门用于解决同名实体产生歧义问题的技术。通过实体消歧能够根据当前语境,结合上下文准确建立实体链接,而实现实体消歧义主要采用聚类算法。(类似词性消歧和词义消歧)
共指消解:主要用于解决多个指称对应同一实体对象的问题。多个指称可能指向的是同一个实体对象,而利用共指消解技术,可以将这些指称项关联到正确的实体对象,由于该问题在信息检索和自然语言处理等领域具有特殊重要性,吸引了大量的研究。共指消解还有一些其他的名字,例如对象对齐、实体匹配、实体同义等
Part III - B - 2:知识合并
在开始这个过程之前,我们假设已经完成了实体链接 ,也就是将实体链接到知识库中对应的正确实体对象,但是需要强调的是,实体链接时所链接的是从半结构化数据以及非结构化数据中通过信息抽取得到的数据。那么除了这两类之外,还有更方便的数据来源,即结构化数据,如外部知识库或关系数据库。
对于这部分结构化数据的处理即为知识合并,一般来说为两种:外部知识库合并 以及 关系数据库合并。
在进行外部知识库合并时,主要处理两个层面的问题:
- 数据层的融合,包括实体的指称、属性、关系以及所属类别等,主要的问题是如何避免实例以及关系的冲突问题,消除不必要的冗余
- 模式层的融合,将新得到的本体融入已有的本体库中
一般情况下可以按照下列四个步骤:
- 获取知识
- 概念匹配
- 实体匹配
- 知识评估
关系数据库合并:在构建知识图谱的过程中,一个重要的高质量知识来源是企业或者机构自己的关系数据库。为了将这些结构化的历史数据融入到知识图谱中,可以采用**资源描述框架(RDF)**作为数据模型,这一个数据转换的过程被成为RDB2RDF ,意为将关系数据库的数据换成RDF的三元组数据。
Part III - C:知识加工
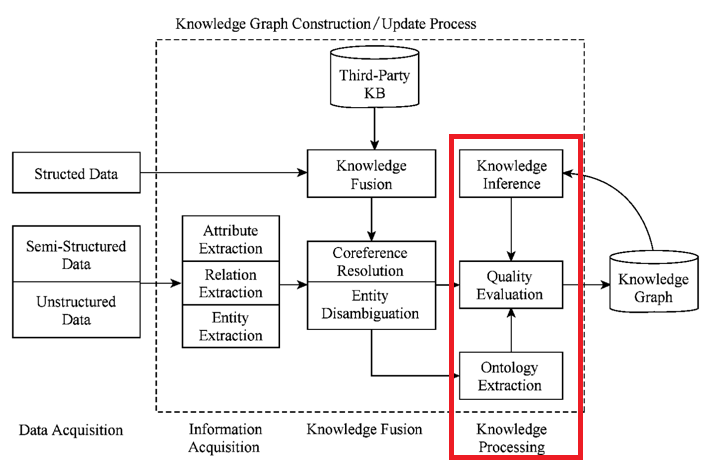
重复看KG的技术架构图,在前面两个步骤中我们已经通过了信息抽取,从原始语料中提取了实体、关系与属性等知识要数,并且经过知识融合,消除了实体指称项与实体对象之间的歧义,得到了一系列基本的事实表达。但是事实本身并不意味着等于知识,想要获得结构化的最终体,网络化的知识体系,还需要经过知识加工的过程。
知识加工主要包括:本体构建、知识推理,以及质量评估
Part III - C - 1:本体构建
**本体(Ontology)**是对概念进行建模的规范,是描述客观世界的抽象模型,以一种形象化的方式对概念以及之间的关系给出明确的定义。本体最大的特点是共享,本体中反映的知识是一种明确定义的知识。在知识图谱中,本体位于 模式层,用来描述概念层次体系,是知识库中知识的概念模板。
本体可以采用人工编辑的方法,通过本体编辑软件来手动构建,但是付出的工作量将会是巨大的。一般来说可以以数据驱动的自动化方式来构建本体。一些面向特定领域自动化本体构建过程包含三个阶段:
- 实体并列关系相似度:
- 考察任意两个给定的实体在多大的程度上术语同一概念的指标测度,相似度越高,则越加表明这两个实体可能属于同一语义类别。例如
中国\美国,这是国家的实体名称,具有较高的并列关系相似度,但是中国\计算机这两个实体名称之间的并列关系相似度就是极低的。 - **主流计算方法:**模式匹配法和分布相似度。
- 考察任意两个给定的实体在多大的程度上术语同一概念的指标测度,相似度越高,则越加表明这两个实体可能属于同一语义类别。例如
- 实体上下位关系抽取:
- 用于确定概念之间的隶属问题,也就是 IsA 关系,这种关系也被称之为上下位关系。例如
硬件\磁盘就构成了上下位关系,磁盘为下位词,而硬件为上位词。 - 主要研究方法: ①基于语法模式(如Hearst模式)抽取IsA实体对;②利用概率模型来判定IsA关系和区分上下位词,通常会借助一些百科类网站提供的概念分类知识来帮助训练模型,用以提高算法的精度;③用跨语言知识链接的方法来构建本体库;
- 用于确定概念之间的隶属问题,也就是 IsA 关系,这种关系也被称之为上下位关系。例如
- 本体的生成
- 本体生成主要是对各个层次得到的概念进行聚类,并且对其进行语义类的标定,为该类中的实体制定一个或多个公共上位词。
- 主要研究方法:实体聚类方法。
Part III - C - 2:知识推理
知识推理是从知识库中已有的实体关系数据出发,进行计算机推理,建立实体间的新关联,从而不断的扩展整个知识网络。知识推理也是知识图谱构建的重要手段和环节之一,通过知识推理,能够从现有知识中发现新的知识。例如说我们得知了这样的两个三元组,(A君,父亲,B君),(B君,弟弟,C君)从而我们能够得知(A君,父亲,C君)。
除此外知识推理的对象也可以是实体的属性值,本体的概念层次关系等。拿属性值推理来说:当你知道一个人的出生年月日,那么也就能够得知他的年龄,所属时代等。
知识的推理方法可以分为2大类:基于逻辑的推理和基于图的推理。
- 基于逻辑的推理
- 一阶谓词逻辑:命题被分解为个体(individuals)和谓词(predication)两个部分。个体指的是可以独立存在的客观个体,也可以是一个具体的事物或者抽象的概念。而谓词是刻画个体性质以事物关系的词。比如
(A君,朋友,B君),朋友就是表达个体A君和个体B君关系的谓词。 - 描述逻辑:对于比较复杂的实体关系,可以采用描述逻辑进行知识推理。这是一种基于对象的知识表示的形式化工具,是一阶谓词逻辑的子集,是本体语言推理的重要设计基础。
- 基于规则的推理:可以利用专门的规则语言,比如SWRL(Semantic Web Rule Language)
- 一阶谓词逻辑:命题被分解为个体(individuals)和谓词(predication)两个部分。个体指的是可以独立存在的客观个体,也可以是一个具体的事物或者抽象的概念。而谓词是刻画个体性质以事物关系的词。比如
- 基于图的推理
- 主要基于神经网络模型或者Path Ranking 算法。Path Ranking 算法的基本思想是将知识图谱视为图,从源节点开始,在图上执行随机的游走,如果能够通过一个路径达到目标节点,则可以推出源节点和目标节点存在关系。
Part III - C - 3:质量评估
质量评估也是知识库构建技术的重要组成部分,这一部分存在的意义在于:可以对知识的可信度进行量化,通过舍弃置信度较低的知识来保障知识库的质量。
Part IV :知识图谱的更新
从逻辑上看,知识库的更新包括概念层的更新和数据层的更新。
- 概念层的更新是指新增数据后获得了新的概念,需要自动将新的概念添加到知识库的概念层中。
- 数据层的更新主要是新增或更新实体、关系、属性值,对数据层进行更新需要考虑数据源的可靠性、数据的一致性(是否存在矛盾或冗杂等问题)等可靠数据源,并选择在各数据源中出现频率高的事实和属性加入知识库。
知识图谱的内容更新有两种方式:
- **全面更新:**指以更新后的全部数据为输入,从零开始构建知识图谱。这种方法比较简单,但资源消耗大,而且需要耗费大量人力资源进行系统维护;
- **增量更新:**以当前新增数据为输入,向现有知识图谱中添加新增知识。这种方式资源消耗小,但目前仍需要大量人工干预(定义规则等),因此实施起来十分困难。
Other I:知识图谱的应用
通过知识图谱,不仅可以将互联网的信息表达成更接近人类认知世界的形式,而且提供了一种更好的组织、管理和利用海量信息的方式。目前的知识图谱技术主要用于智能语义搜索、移动个人助理(例如:苹果的Siri,小米的小爱)以及深度问答系统(Watson),支撑这些应用的核心技术正是知识图谱技术。
在智能语义搜索中,当用户发起查询时,搜索引擎会借助知识图谱的帮助对用户查询的关键词进行解析和推理,进而将其映射到知识图谱中的一个或一组概念之上,然后根据知识图谱的概念层次结构,向用户返回图形化的知识结构,这就是我们在谷歌和百度的搜索结果中看到的知识卡片。目前知识图谱最成熟的一个场景就是智能语义搜索。
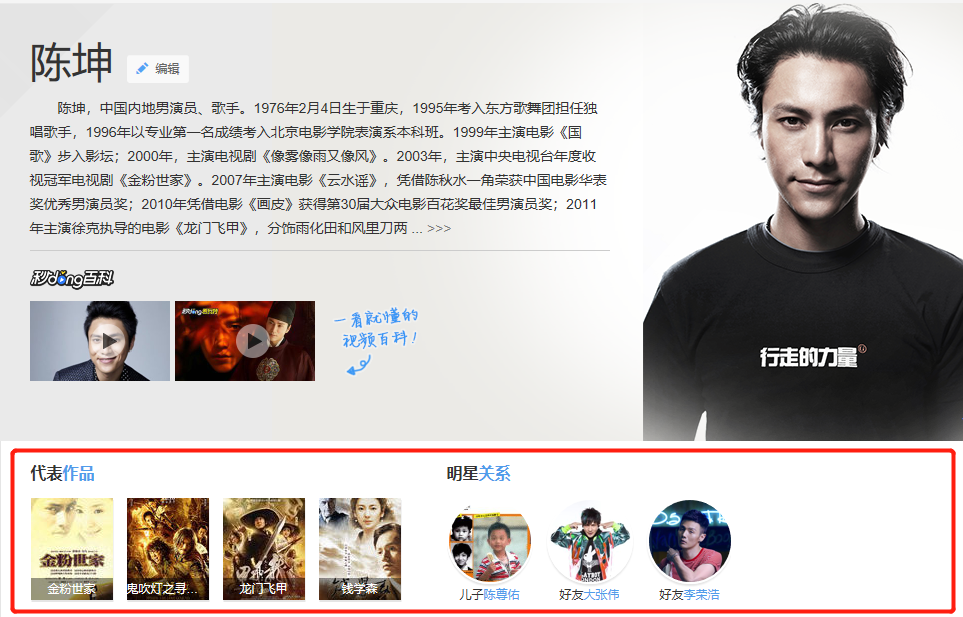
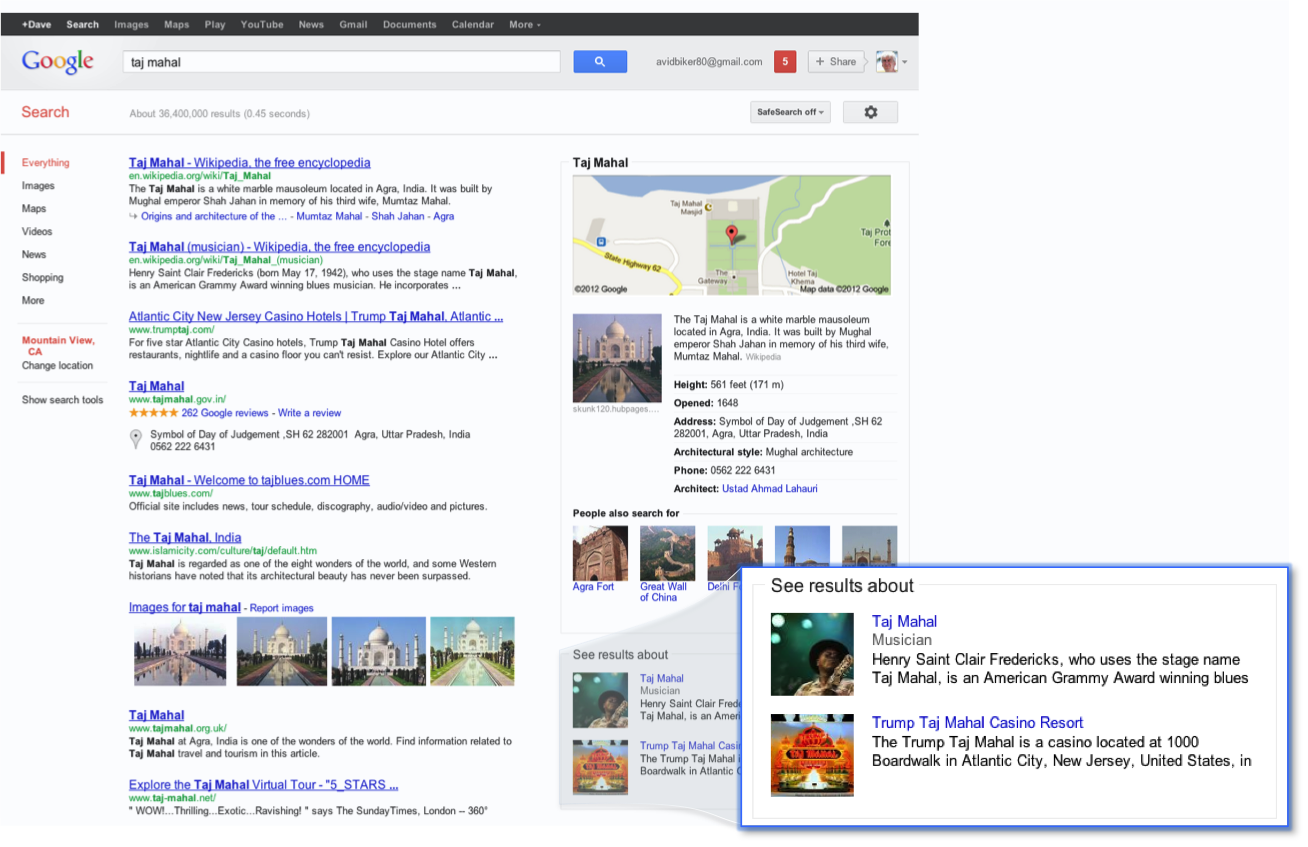
在深度问答应用中,系统同样会首先在知识图谱的帮助下对用户使用自然语言提出的问题进行语义分析和语法分析,进而将其转化成结构化形式的查询语句,然后在知识图谱中查询答案。比如,如果用户提问:**如何判断是否感染了埃博拉病毒?则该查询有可能被等价变换为埃博拉病毒的症状有哪些?**然后再进行推理变换,最终形成等价的三元组查询语句,如(埃博拉,症状,?)和(埃博拉,征兆,?)等。如果由于知识库不完善而无法通过推理解答用户的问题,深度问答系统还可以利用搜索引擎向用户反馈搜索结果,同时根据搜索结果更新知识库,从而为回答后续的提问提前做出准备。
除此之外,知识图谱的应用还有许多,例如:
- 客户管理(适用于多种企业领域): 通过构建客户人物关系知识图谱,更好的进行客户信息、关系等管理,挖掘出更多的联系人。
- 精准销售分析(适用于多种企业领域):一个聪明的企业可以比它的竞争对手以更为有效的方式去挖掘其潜在的客户。在互联网时代,销售手段多种多样,但不管有多少种方式,都离不开一个核心——分析用户和理解用户。知识图谱可以结合多种数据源去分析实体之间的关系,从而对用户的行为有更好的理解。比如一个公司的市场经理用知识图谱来分析用户之间的关系,去发现一个组织的共同喜好,从而可以有针对性的对某一类人群制定营销策略。只有我们能更好的、更深入的理解用户的需求,才能更好地去做销售。
- 不一致性验证(银行、证券公司):可以用来判断一个借款人的欺诈风险,这个跟交叉验证类似。比如借款人张三和借款人李四填写的是同一个公司电话,但张三填写的公司和李四填写的公司完全不一样,这就成了一个风险点,需要审核人员格外的注意。再比如,借款人说跟张三是朋友关系,跟李四是父子关系。当我们试图把借款人的信息添加到知识图谱里的时候,“一致性验证”引擎会触发。引擎首先会去读取张三和李四的关系,从而去验证这个“三角关系”是否正确。很显然,朋友的朋友不是父子关系,所以存在着明显的不一致性。不一致性验证涉及到知识的推理。通俗地讲,知识的推理可以理解成“链接预测”,也就是从已有的关系图谱里推导出新的关系或链接。 比如在上面的例子,假设张三和李四是朋友关系,而且张三和借款人也是朋友关系,那我们可以推理出借款人和李四也是朋友关系。
Other II:国内外开放的知识图谱
随着知识图谱的概念不断兴起,国内外许多搜索引擎公司和科研机构发布和维护了各类大规模知识库 ,其中有Google 收购的 Freebase 、德国莱比锡大学等机构发起的项目 DBpedia 、德国马普研究所开发的链接数据库 YAGO 、普林斯顿大学开发的语义词典 wordnet 等,国内的如中文知识图谱社区 OpenKG.CN 等

参考资料/文献
【1】Open-World Knowledge Graph Completion - Baoxu Shi& Tim Weninger - University of Notre Dame - Github Code Link
【2】Knowledge Graph - Wikipedia
【3】How to build a Knowledge Graph - Stack Overflow : Kikohs
【4】De Abreu, D., Flores, A., Palma, G., Pestana, V., Pinero, J., Queipo, J., … & Vidal, M. E. (2013). Choosing Between Graph Databases and RDF Engines for Consuming and Mining Linked Data. In COLD.
【5】Bordes, A., Usunier, N., Garcia-Duran, A., Weston, J., & Yakhnenko, O. (2013). Translating embeddings for modeling multi-relational data. In Advances in Neural Information Processing Systems (pp. 2787-2795).
【6】Socher, R., Chen, D., Manning, C. D., & Ng, A. (2013). Reasoning with neural tensor networks for knowledge base completion. In Advances in Neural Information Processing Systems (pp. 926-934).
【7】金融知识图谱搭建全攻略 - 知乎 - 深度学习与NLP
 微信
微信 支付宝
支付宝